
如何運用AI協助資產管理--筆記系列(2)
從 Spectral Clustering 到市場 Regime 的理解
0. 引言:從「股票分群」到「市場分群」
在前一篇,我們提到可以用 k-means 去理解股票之間的風險結構。那篇文章的核心其實很簡單:我們不應該把市場視為一個整體,而應該是由不同「行為群」組成。
但如果把問題再想深入一點呢:股票之間可以分群,那市場本身呢?
也就是說:
股票有風格(growth / defensive / cyclical)
那市場,有沒有「狀態」?
這就是 regime(經濟環境)的問題。而在這一層分類,k-means這方法就開始不夠用了。所以本篇會介紹Spectral Clustering、學術根本、實務應用、及這方法如何改變資產管理。
1. Spectral Clustering:方法與直覺
1.1 與 k-means 的根本差異
在機器學習的分類中,clustering 大致可以分成兩類:
distance-based(距離導向)→ k-means
graph-based(關係導向)→ spectral clustering
k-means 的邏輯是資料離分群中心最近,就會被分到同一群;但這隱含了一個假設:群是「圓形」的。但金融市場資料通常不是這樣,因為:
成長與通膨之間可能呈現曲線關係
信用條件與報酬之間可能非線性
macro variables 常具有 regime switching 特性
所以這些結構,用距離是抓不到的。
1.2 Spectral Clustering 在做什麼
Spectral clustering 的思路不同。
它先做三件事:
建立 similarity matrix(相似度矩陣)
將資料轉換成 graph(圖結構)
在 graph 上做切割(partition)
直觀理解:它不是像K-mean 問「誰比較近」,而是問「誰跟誰比較有連結」;而這個「連結」通常用 Gaussian kernel 表示:
接著透過 Laplacian matrix:
再取其特徵向量(eigenvectors),把問題轉換到低維空間後,再做 clustering。
1.3 為什麼適合用在市場 Regime
這裡的關鍵其實並不是數學,而是經濟直覺,因為市場狀態(regime)通常具有以下特性:
非線性(nonlinear relationships)
轉換不連續(regime switching)
多變數交互作用(interaction effects)
例如:
高通膨 + 高利率 ≠ 單純兩個變數相加
信用緊縮通常伴隨 liquidity shock
成長與通膨的組合決定資產表現
這些結構,本質上更像「網絡」,而不是「幾個圓」。因此spectral clustering 更適合用來辨識市場狀態。
2. 文獻脈絡
2.1 Simonian & Wu (2019)
Simonian 與 Wu(2019)的貢獻在於:將 spectral clustering 直接應用於市場 regime 分類。
其核心設定為三個 macro 因子:
Growth(成長)
Inflation(通膨)
Leverage / Credit(信用條件)
透過這三個變數,模型將市場分成幾個主要狀態,例如:
成長擴張(Goldilocks Expansion)
通膨衝擊(Inflation Shock)
信用壓力(Credit Stress)
復甦轉換(Recovery Transition)
這種分類的特點是:
不依賴預測
完全由資料結構決定
可直接對應資產配置
2.2 López de Prado et al.(2025)
該篇作者更進一步把 ML 放進整個投資流程:
signal generation
feature selection
portfolio construction
stress testing
其中一個關鍵點是clustering 被定位為「結構辨識工具」,而非預測模型;原文中明確指出:Unsupervised learning 的目標是從資料中找出 hidden structure
這代表:
clustering 不是用來預測報酬
而是用來理解市場如何運作
此外,文章也提到:
spectral clustering 可用於 regime-based modeling
clustering 可強化 stress testing 與 scenario analysis
這與 Simonian & Wu 的架構是一致的。
2.3 從股票到市場的兩層結構
整理起來,可以看到一個清楚的層次:
第一層:股票之間的結構(k-means / clustering)
第二層:市場本身的結構(spectral / regime)
這兩層其實對應不同問題:stock selection和asset allocation
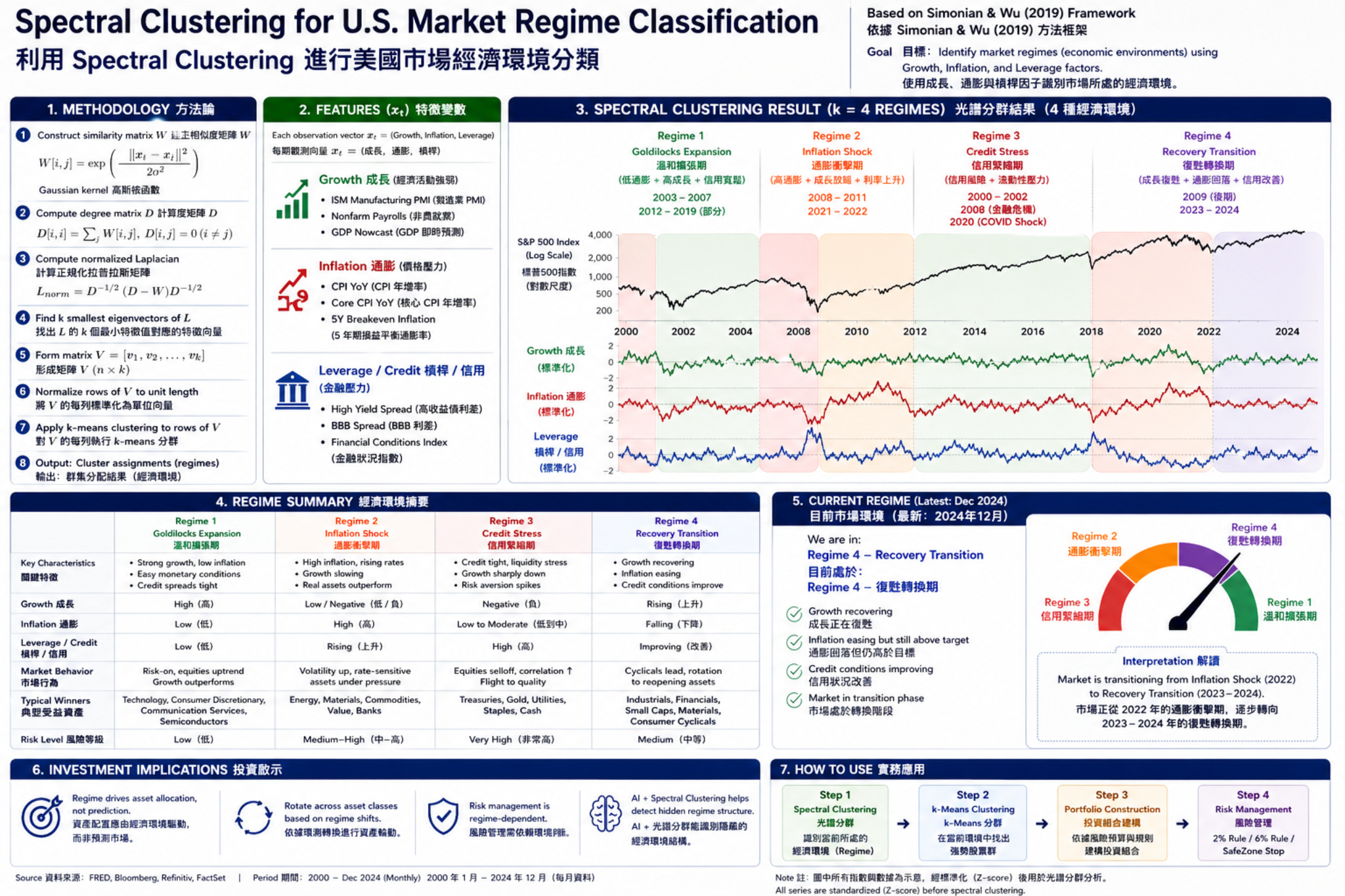
3. 實際應用
上圖為利用 Spectral Clustering 辨識市場 Regime,這張圖呈現了一個完整的實務框架:我們必須先知道不是用AI模型預測市場,而是先回答:市場目前處在什麼狀態?
模型的核心輸入變數來自三個 macro 維度:
Growth(經濟成長)
ISM / PMI
Nonfarm Payrolls
GDP
Inflation(通膨)
CPI / Core CPI
Breakeven Inflation
Leverage / Credit(信用條件)
High Yield Spread
BBB Spread
Financial Conditions Index
這三組變數代表了經濟環境的三個主要驅動力;接著透過 spectral clustering,把這些時間序列轉換成:不同的市場狀態(regimes)
3.2 分群結果(四種市場狀態)
模型將市場分為四個主要 regime:
Regime 1:成長擴張(Goldilocks Expansion)
特徵:
高成長
低通膨
信用寬鬆
市場行為:
股市上行
波動較低
典型資產:
科技股
成長股
Regime 2:通膨衝擊(Inflation Shock)
特徵:
通膨上升
利率走高
市場行為:
成長股壓力
原物料、能源相對強勢
Regime 3:信用壓力(Credit Stress)
特徵:
信用利差擴大
流動性收縮
市場行為:
風險資產下跌
避險需求上升
Regime 4:復甦轉換(Recovery Transition)
特徵:
成長回升
通膨緩解
信用改善
市場行為:
cyclical rotation
小型股與工業類股表現改善
3.3 關鍵 insight:Clustering 改變你看市場的方式
這裡有一個結構性的轉換,和上一篇是對應的。在傳統投資框架中,我們通常這樣理解市場:
牛市 / 熊市
景氣好 / 景氣差
利率高 / 利率低
但這些分類大多是單一維度的判斷。但透過 spectral clustering,市場可被重新定義為:
成長 × 通膨 × 信用條件的組合
這兩個分類的本質差異是一個是「單一變數」,一個是「結構組合」。這符合投資的直覺:市場真正影響資產報酬的,往往不是單一變數,而是多個 macro 因子的交互作用。
4. 傳統資產管理 vs AI 資產管理
傳統資產管理的核心,是預測。像我們在財務管理會建立模型,估計未來報酬、風險與相關性,再依此進行資產配置。無論是基本面分析、因子模型,或是均值變異數架構,本質上都建立在同一個前提:如果預測足夠接近現實,配置就會是合理的。
但實務上的問題在於,預測本身並不穩定。市場並不是一個固定結構的系統。成長、通膨、利率與信用條件之間的關係,都會隨時間不斷地改變。在不同階段,相同的變數,可能對資產價格產生完全不同的影響。
在這樣的背景下,機器學習的方法並沒有真正解決「預測」這個問題。它改變的,是我們處理問題的順序。從一開始就試圖預測市場,轉為先理解市場目前的結構,再進行決策。
在這個框架下,投資流程會變成:
先辨識市場狀態(regime)
再選擇對應的策略
最後才是資產配置
這個順序的改變,看起來只是技術上的調整,但實際上影響的是整個決策邏輯。
我們可以說明這樣的轉換,會帶來兩個直接影響。
第一,它降低了對預測精度的依賴。即使無法精準預測報酬,只要能辨識出市場環境,仍然可以做出合理配置。
第二,它讓資產配置有了更清楚的依據。策略不再是固定的,而是依據市場狀態做調整。
換句話說,機器學習在資產管理中的角色,並不是提供更複雜的模型,而是讓我們用比較清晰的方式理解市場。
不是預測未來,而是先界定現在。
如果把整個架構再簡化成一句話:這也是為什麼,clustering 與 spectral clustering 的價值,不在於它們能產生更準確的預測結果,重點在於:它們讓投資決策,有了一個比較穩定的起點。
風險揭露
本文僅供學術與教育用途,不構成投資建議。文中分析為方法示範,結果受資料與模型設定影響,過去表現不代表未來,投資需自行承擔風險。
AI 輔助揭示
本文使用 AI 協助整理與表達,觀點與分析由作者獨立完成並審閱。