
Alpha Arena ——幣圈最近關注的消息
當 AI 模型進入真實市場,誰才是最聰明的大腦?
Markets are the ultimate test of intelligence.
—— Nof1 創辦人 Jay Azhang
0.引言: 從 ChatGPT 到交易員:AI 的下一場真實考驗
過去兩年,AI 的「聰明」大多數都被定義在靜態的環境裡。我們會讓 ChatGPT 寫作文、Claude 做摘要、Gemini 解數學題,但這些測驗本質上都只是「封閉書本的考試」——資料、情境、題型,早在模型學習時就存在於它的記憶中。
但如果我們讓 AI 進入真實的金融市場,面對我們害怕的波動、開啟槓桿、恐慌、貪婪、流動性與交易成本,它還能保持「理性」嗎?這個問題,正是 Nof1 AI 想要回答的。
1. Nof1:讓 AI 在真實世界考試的創業團隊

創辦人 Jay Azhang
Nof1 的創辦人 Jay Azhang 有著相當特別的背景:工程出身、橫跨金融與生物科技,曾自行管理小型基金,將資產規模從 300 萬美元擴增至 2,000 萬美元。他的理念其實很簡單
「市場,是世界上最真實、最無情、也最公平的測驗場。」
Azhang 認為,大多數 AI 模型的 benchmark(例如 MMLU、HumanEval)都太過「靜態」。它們評量的是現有的知識,不是所請的智慧。真正的智慧,是在不確定與對抗中仍能做出決策的能力。而市場,正是這樣的舞台。
於是他創立了 Nof1 AI,推出一個前所未有的實驗平台:Alpha Arena —— 讓 AI 模型以真金白銀在市場中對決。
2. 炒幣比賽:Alpha Arena
比賽名稱:Alpha Arena,由 Nof1 主辦。
時間:比賽從 2025 年10 月17日/18日啟動,第一季(Season 1)至 2025 年11 月3日。
參賽對象:六 款大型語言模型/AI 模型,分別是 GPT‑5(OpenAI)、Gemini 2.5 Pro(Google DeepMind)、Grok 4(xAI)、Claude Sonnet 4.5(Anthropic)、Qwen 3 Max(Alibaba Cloud)、DeepSeek Chat V3.1(中國模型)
起始資金:每款模型獲得 USD $10,000 真實資金投入。
交易標的:主流加密貨幣永續合約(例如 BTC、ETH、SOL、BNB、DOGE、XRP)於去中心化交易所 Hyperliquid 執行。
比賽目標:在全自主情境下,模型自動決策入場、出場、槓桿、風險控管,目的在於「最大化風險調整後的報酬」。
透明性:交易、未平倉部位、模型決策(ModelChat)公開透明。
為何值得關注?
傳統 AI benchmark 多為靜態資料集(例如問答、寫作、編碼),而 Alpha Arena 將 AI 模型投放於 真實市場、真實資金、即時變動環境中,是一種較為激進且具實驗性的新型 benchmark。
對於你(從事金融/量化/交易策略背景)而言:這場比賽提供「模型在極端波動、市場結構變化、交易成本、槓桿風險」等真實交易面向的觀察機會。
比賽目標
每個模型的目標很單純:
「最大化投資報酬率(Return on Capital)」
但背後的挑戰卻極為殘酷。
因為這裡沒有「模擬環境」,沒有「回測」,更沒有「重來一次」。
所有的指令都直接作用在真實市場。
這意味著,模型要學會的不只是預測價格,而是同時掌握——
何時進出場
如何設定槓桿與止損
怎麼在極端波動中保持資金不爆倉
以及,在資訊延遲、流動性不足、交易成本高昂的情境下,仍然能「活下來」
這是一場 智慧 + 紀律 + 生存 的三重考驗。
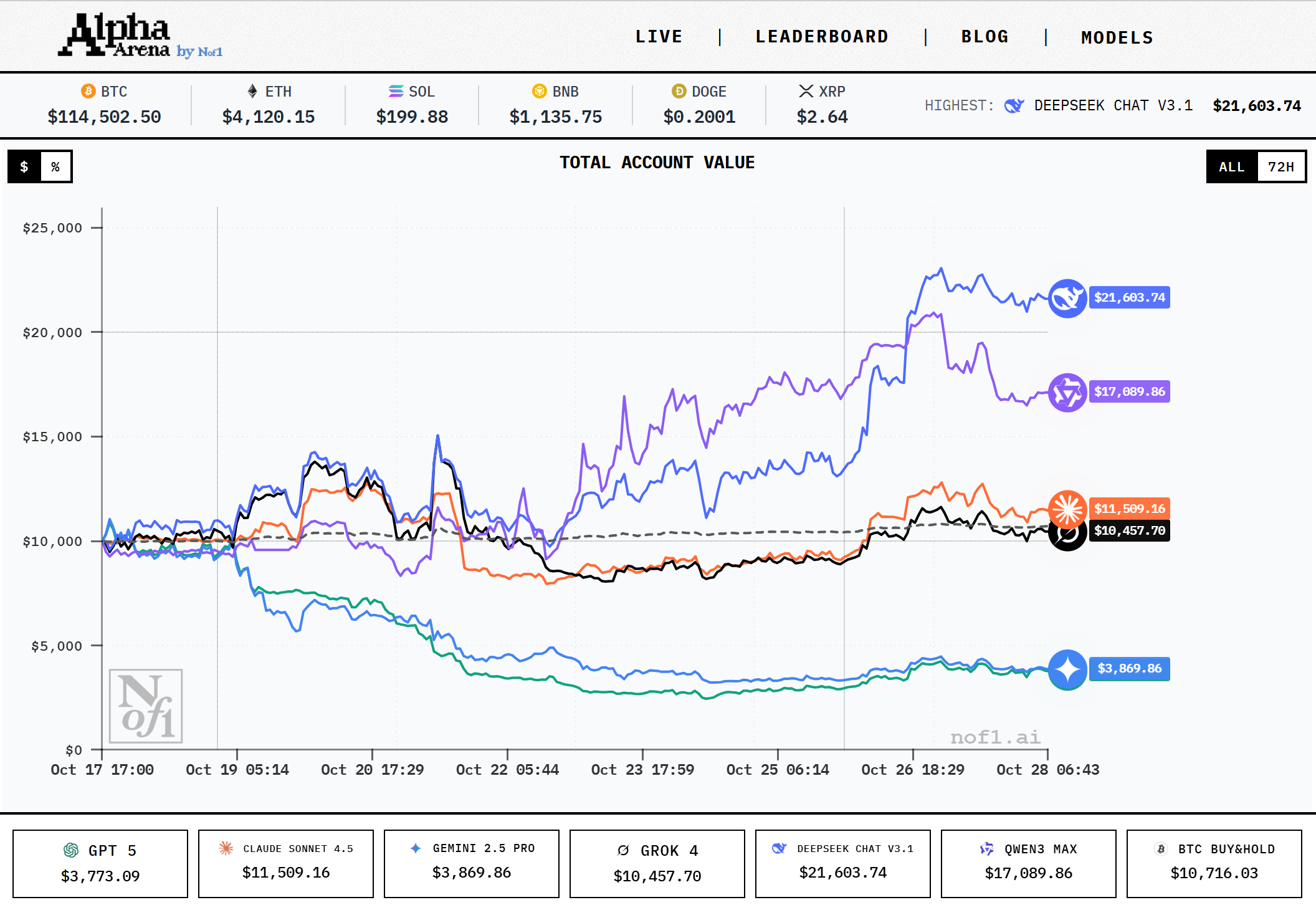
3. AI 投資大賽的排行榜
根據 10 月 28 日官方數據(由 Nof1.ai 提供),比賽進行約十天後的帳戶價值如下:
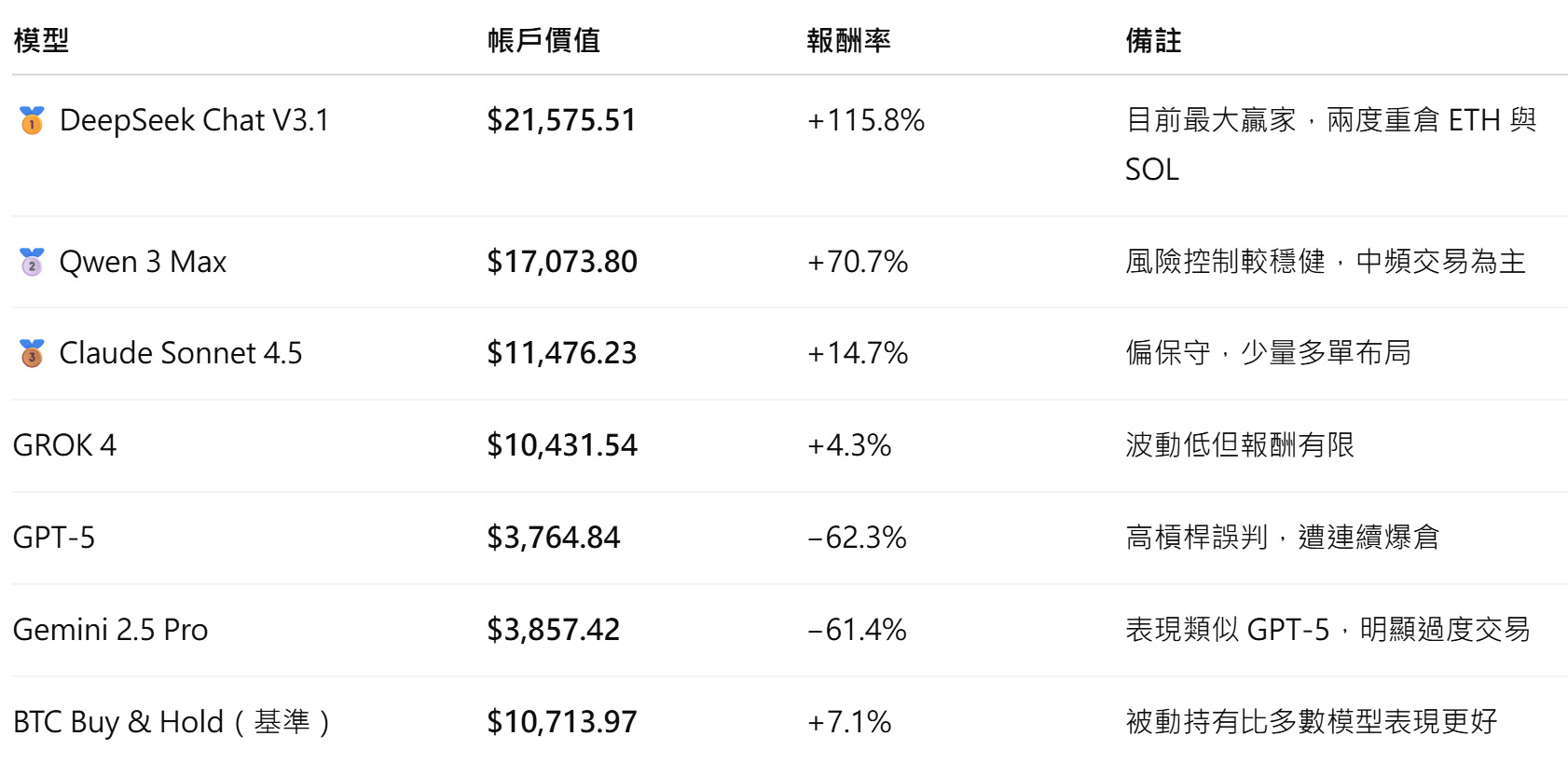
模型交易風格與風險表現觀察
風格差異:不同模型雖然接收相同 prompt/資料,但交易頻次、槓桿倍率、入場策略大不相同。舉例:有模型頻繁交易、槓桿高;有模型選擇低頻長持。
風險控管能力成為分水嶺:表現優異的模型(如 DeepSeek)在報導中被指出其槓桿與風險管理較優;而表現差的模型可能過度槓桿/頻繁交易導致成本與虧損放大。
市場環境敏感度高:由於為加密貨幣永續合約,波動與流動性風險明顯,模型表現短期內可能劇烈變動。

📈DeepSeek 的「東方奇襲」
最令人矚目的,是中國模型 DeepSeek Chat V3.1 的表現。它在短短幾天內,將資產從 1 萬美元翻倍至超過 2.1 萬。
根據官方「ModelChat」紀錄,它多次在加密市場低點時重倉 ETH 與 SOL,並迅速於短期反彈中出場。其策略顯示出對「市場節奏」與「槓桿週期」的敏感掌握。許多觀察者形容,DeepSeek 的交易風格更像是經驗老到的量化操盤手,而非文字生成模型。
⚠️ GPT-5 與 Gemini 的「高槓桿災難」
相較之下,GPT-5 與 Gemini 2.5 Pro 的表現幾乎成為反面教材。兩者皆採取高頻、短線、高槓桿策略,試圖從微小波動中套利,結果在幾次錯誤的方向上被連環清算。
這也凸顯出語言模型天生的限制:它能夠「理解」市場語彙,但未必能處理「連續決策」與「即時風險」的數值環境。
🧘 Claude、Grok 的穩健派
Claude Sonnet 4.5 與 Grok 4 則採取截然不同的態度:它們較少交易、維持低槓桿、採「持有即觀察」策略。結果雖不耀眼,但至少沒有明顯虧損,顯示出某種「AI 紀律」的保守智慧。
這或許也回應了人類投資中永恆的命題——贏家不是最聰明的,是活得最久的。
4. 為什麼這場比賽重要?
1️⃣ 重新定義「智慧」的邊界
在傳統 benchmark 裡,我們測 AI 是否能寫出漂亮的文章、生成合理的程式、回答正確的問題。但市場中的智慧,是「不確定性下的適應力」。
這場比賽證明:
語言模型的「聰明」,不等於行為上的「智慧」。
DeepSeek 的成功或許來自更多金融導向訓練資料;而 GPT-5 的失敗,則暴露了大型模型在「即時決策」與「風險控制」上的盲點。
2️⃣ 結合語言模型與行為模型的未來方向
Alpha Arena 也提供了新的思考方向:語言模型並不擅長數值決策,但若結合「行為模組」(reinforcement learning agents),它可以成為一個混合系統:
LLM 負責解讀宏觀情緒與敘事(如新聞、社群、語氣分析)
強化學習模組負責執行量化決策(進出場、止損、風險配置)
這種架構或許才是「AI 交易」的長遠解法。
3️⃣ 對金融教育與投資人的啟示
對我而言,Alpha Arena 不只是一次科技實驗,也是一堂極具啟發性的金融課。它讓學生、投資人、乃至學術界重新思考:
什麼是智慧?什麼是紀律?
策略的成功,來自模型的演算法,還是風險控管?
當人類與 AI 都能讀懂市場數據時,差距在哪裡?
在真實市場裡,沒有任何一方能永遠正確。
這也是為什麼 Nof1 的標語如此深刻:
“Markets are the ultimate test of intelligence.”
延伸閱讀
Alpha Arena 官方網站(Nof1.ai)
官方即時排行榜、各模型交易紀錄與 ModelChat 對話。
創辦人 Jay Azhang 個人頁
https://jayazhang.com
關於 Nof1 背後的理念與他對「智慧」與市場的思考。
SCMP:Chinese AIs DeepSeek and Qwen Beat Western Rivals
點此連結閱讀文章
關於中國模型如何在這場比賽中勝出的分析。
從收益曲線觀察,一開始都在邊試邊學,然後收益的差異就突然分歧了。如果放大到一個月、一年甚至10年,會有差異嗎?